

Edition 5
Table of Contents
List of Figures
Table of Contents
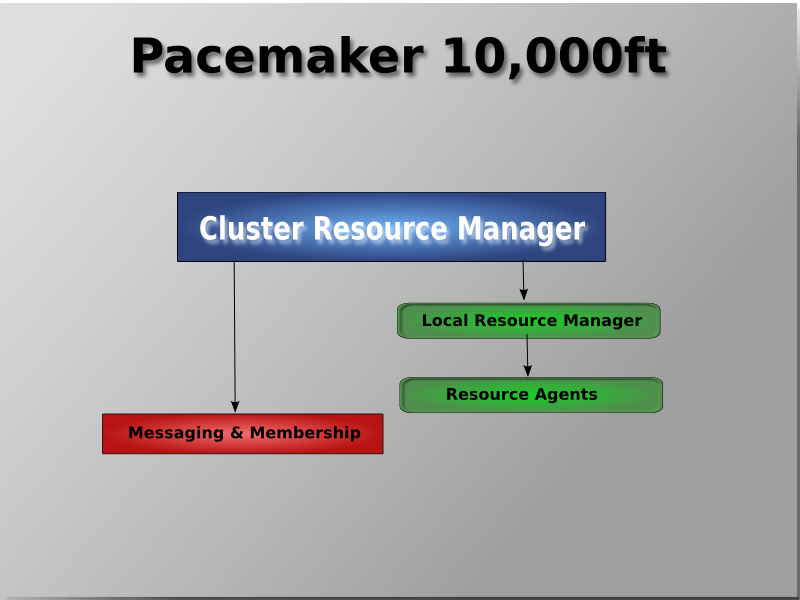
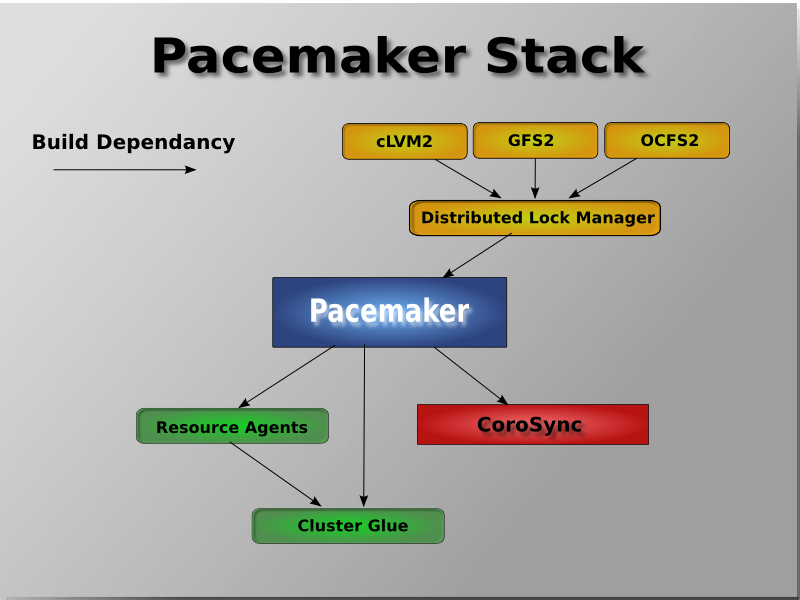
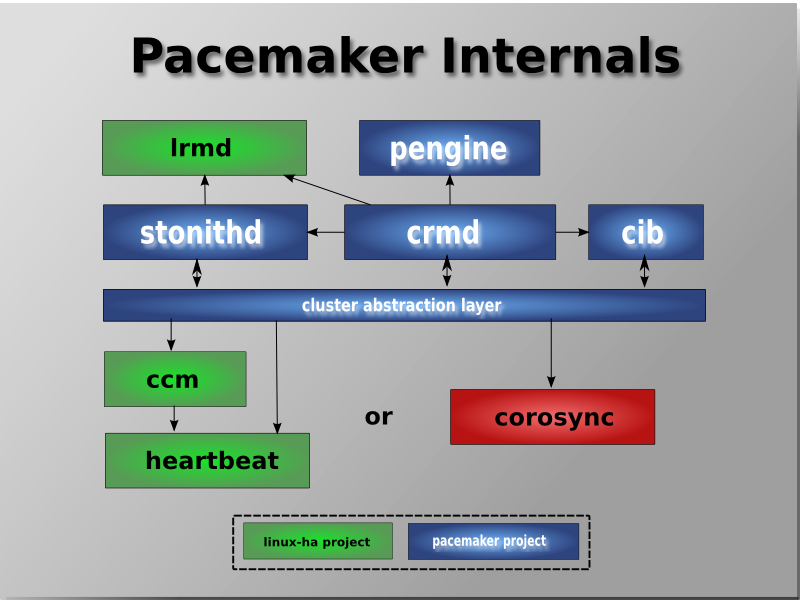
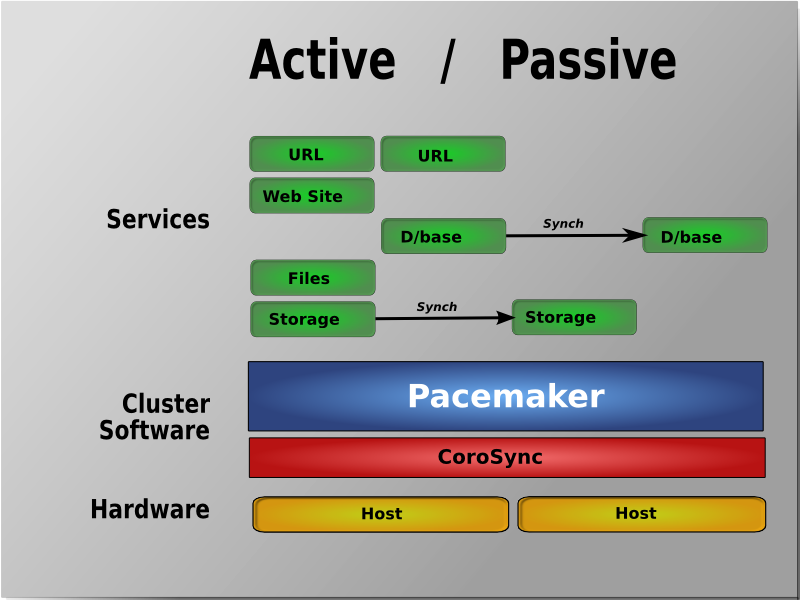
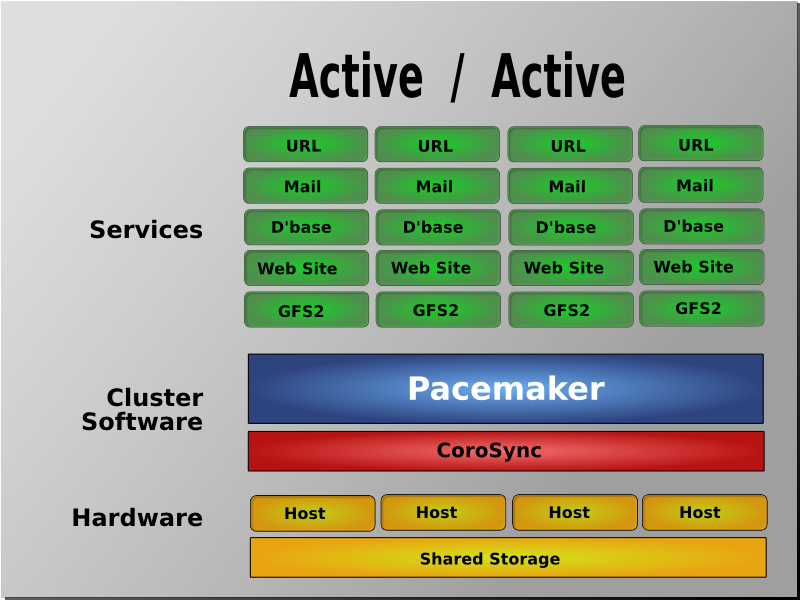
Table of Contents
Install Media section and download the install DVD that matches your hardware.
Configure Network advanced option, select that option before continuing with the installation process to specify a fixed IPv4 address for System eth0. Be sure to also enter the Routes section and add an entry for your default gateway.
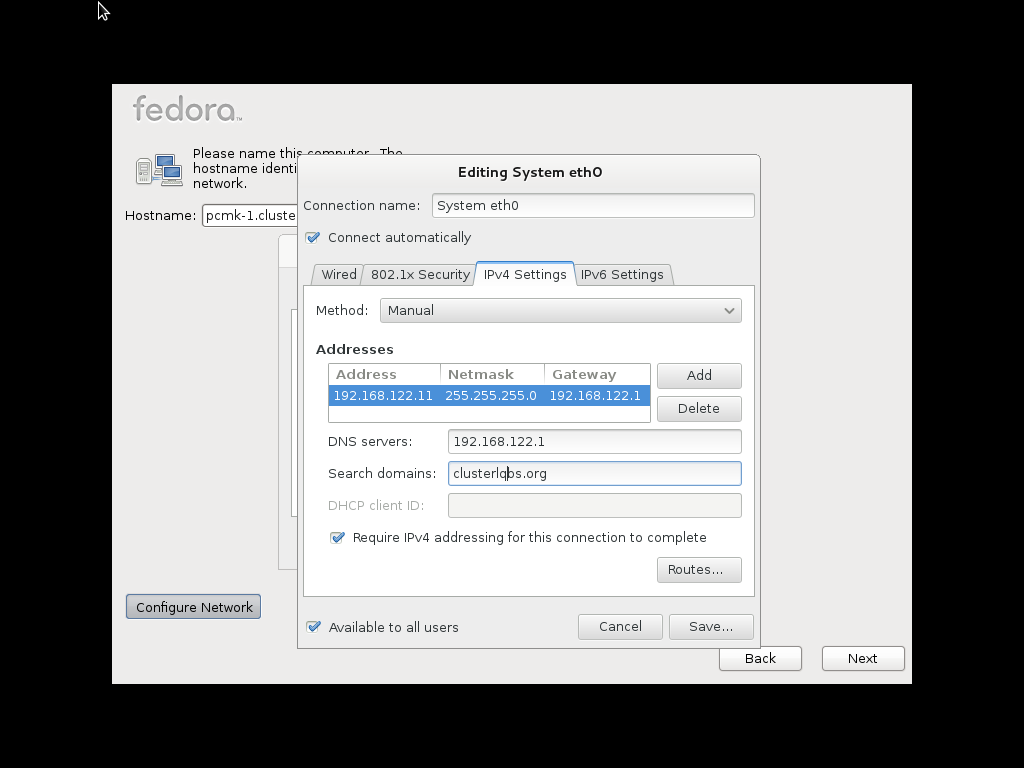
system settings and select network. From there you can select what device to configure.
/ (aka. root) partition which cannot be dynamically reduced in size (dynamic increases are fine by-the-way).
Review and modify partitioning layout checkbox before clicking Next. You will then be given an opportunity to reduce the size of the root partition.
root and the password you created earlier.
# service network start # chkconfig network on
# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:d7:d6:08 brd ff:ff:ff:ff:ff:ff inet 192.168.122.101/24 brd 192.168.122.255 scope global eth0 inet6 fe80::5054:ff:fed7:d608/64 scope link valid_lft forever preferred_lft forever
[root@pcmk-1 ~]# ip route default via 192.168.122.1 dev eth0 192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.101
default via, then you may need to add a line such as
GATEWAY=192.168.122.1# ping -c 1 192.168.122.1 PING 192.168.122.1 (192.168.122.1) 56(84) bytes of data. 64 bytes from 192.168.122.1: icmp_req=1 ttl=64 time=0.249 ms --- 192.168.122.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.249/0.249/0.249/0.000 ms
# ping -c 1 www.google.com PING www.l.google.com (173.194.72.106) 56(84) bytes of data. 64 bytes from tf-in-f106.1e100.net (173.194.72.106): icmp_req=1 ttl=41 time=167 ms --- www.l.google.com ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 167.618/167.618/167.618/0.000 ms
beekhof@f16 ~ # ping -c 1 192.168.122.101 PING 192.168.122.101 (192.168.122.101) 56(84) bytes of data. 64 bytes from 192.168.122.101: icmp_req=1 ttl=64 time=1.01 ms --- 192.168.122.101 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 1.012/1.012/1.012/0.000 ms
beekhof@f16 ~ # ssh -l root 192.168.122.11 root@192.168.122.11's password: Last login: Fri Mar 30 19:41:19 2012 from 192.168.122.1 [root@pcmk-1 ~]#
TODO: Create an Appendix that deals with (at least) re-enabling the firewall.
# setenforce 0 # sed -i.bak "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config # systemctl disable iptables.service # rm '/etc/systemd/system/basic.target.wants/iptables.service' # systemctl stop iptables.service
# uname -n pcmk-1.clusterlabs.org # dnsdomainname clusterlabs.org
# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=pcmk-1.clusterlabs.org GATEWAY=192.168.122.1
# sed -i.sed 's/\.[a-z].*//g' /etc/sysconfig/network# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=pcmk-1 GATEWAY=192.168.122.1
# source /etc/sysconfig/network # hostname $HOSTNAME
# uname -n pcmk-1 # dnsdomainname clusterlabs.org
# ping -c 3 192.168.122.102 PING 192.168.122.102 (192.168.122.102) 56(84) bytes of data. 64 bytes from 192.168.122.102: icmp_seq=1 ttl=64 time=0.343 ms 64 bytes from 192.168.122.102: icmp_seq=2 ttl=64 time=0.402 ms 64 bytes from 192.168.122.102: icmp_seq=3 ttl=64 time=0.558 ms --- 192.168.122.102 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.343/0.434/0.558/0.092 ms
# grep pcmk /etc/hosts 192.168.122.101 pcmk-1.clusterlabs.org pcmk-1 192.168.122.102 pcmk-2.clusterlabs.org pcmk-2
# ping -c 3 pcmk-2 PING pcmk-2.clusterlabs.org (192.168.122.101) 56(84) bytes of data. 64 bytes from pcmk-1.clusterlabs.org (192.168.122.101): icmp_seq=1 ttl=64 time=0.164 ms 64 bytes from pcmk-1.clusterlabs.org (192.168.122.101): icmp_seq=2 ttl=64 time=0.475 ms 64 bytes from pcmk-1.clusterlabs.org (192.168.122.101): icmp_seq=3 ttl=64 time=0.186 ms --- pcmk-2.clusterlabs.org ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2001ms rtt min/avg/max/mdev = 0.164/0.275/0.475/0.141 ms
# ssh-keygen -t dsa -f ~/.ssh/id_dsa -N "" Generating public/private dsa key pair. Your identification has been saved in /root/.ssh/id_dsa. Your public key has been saved in /root/.ssh/id_dsa.pub. The key fingerprint is: 91:09:5c:82:5a:6a:50:08:4e:b2:0c:62:de:cc:74:44 root@pcmk-1.clusterlabs.org The key's randomart image is: +--[ DSA 1024]----+ |==.ooEo.. | |X O + .o o | | * A + | | + . | | . S | | | | | | | | | +-----------------+ # cp .ssh/id_dsa.pub .ssh/authorized_keys
# scp -r .ssh pcmk-2: The authenticity of host 'pcmk-2 (192.168.122.102)' can't be established. RSA key fingerprint is b1:2b:55:93:f1:d9:52:2b:0f:f2:8a:4e:ae:c6:7c:9a. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'pcmk-2,192.168.122.102' (RSA) to the list of known hosts.root@pcmk-2's password: id_dsa.pub 100% 616 0.6KB/s 00:00 id_dsa 100% 672 0.7KB/s 00:00 known_hosts 100% 400 0.4KB/s 00:00 authorized_keys 100% 616 0.6KB/s 00:00 # ssh pcmk-2 -- uname -n pcmk-2 #
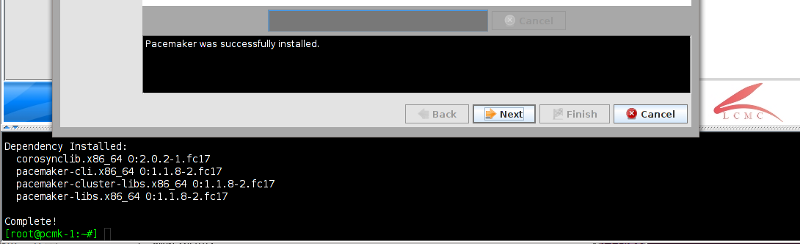
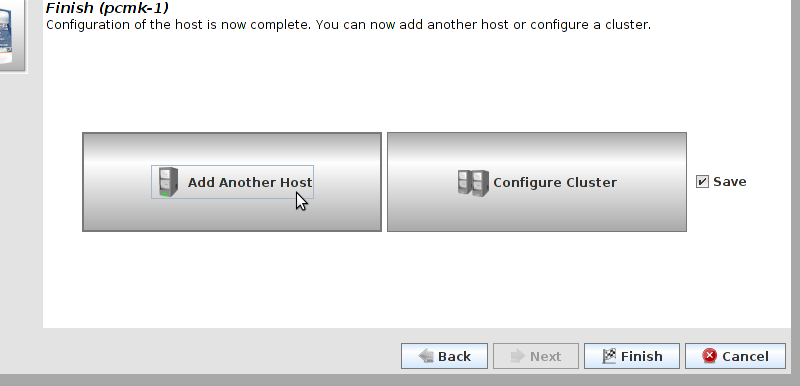
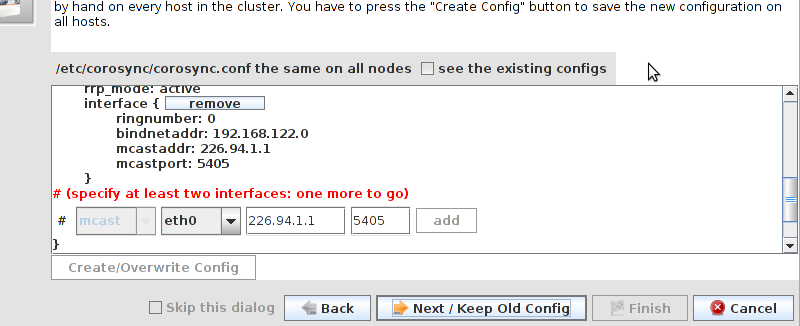
Table of Contents
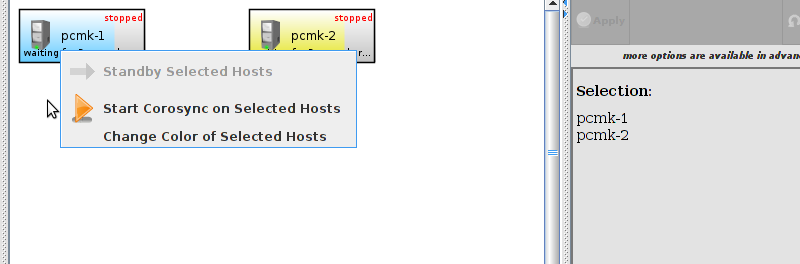
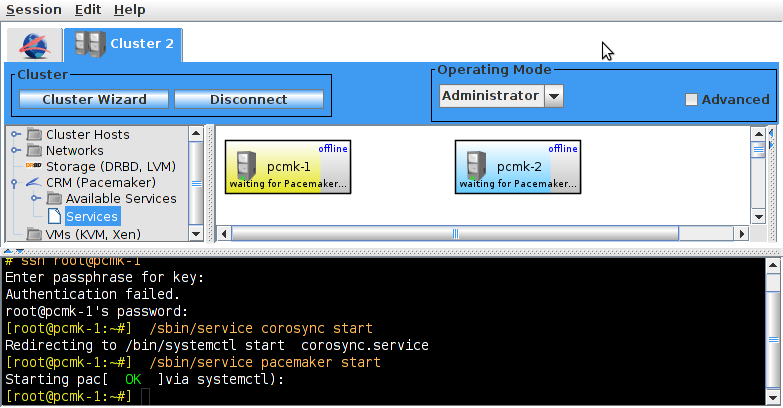
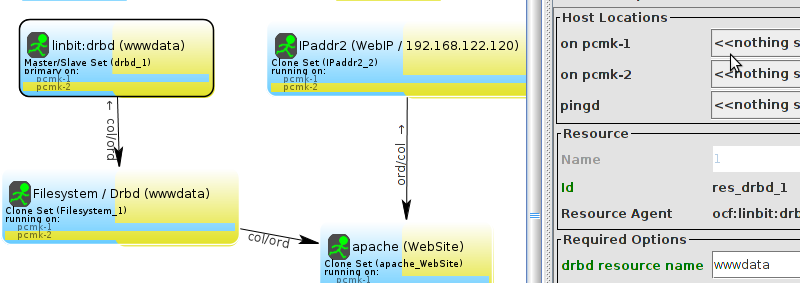
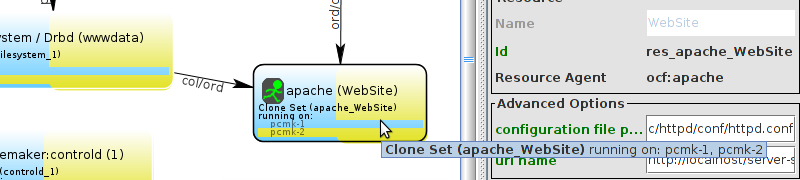
pcs and crmsh. This edition of Clusters from Scratch is based on lcmc. Start by taking some time to familiarize yourself with what it can do.
lcmc has the ability to manage all aspects of the cluster (both corosync and pacemaker), it does not require any specific cluster stack to be in use.
# lcmcTable of Contents
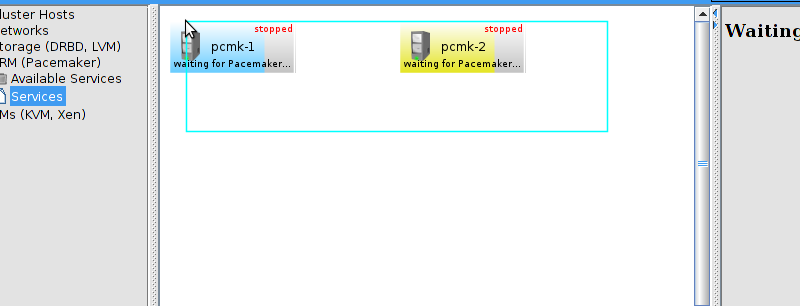

corosync-cfgtool.
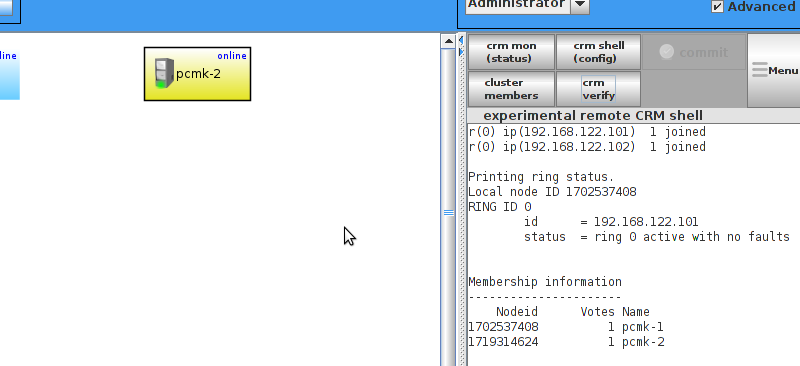
id and no faults for the status.
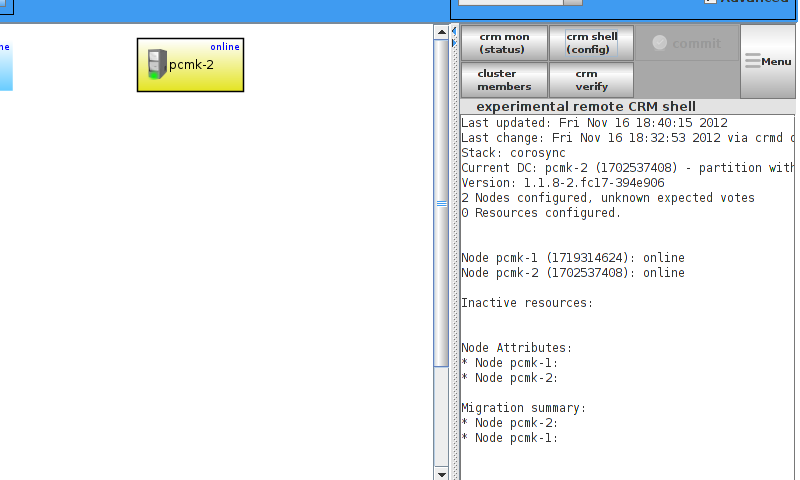
Table of Contents
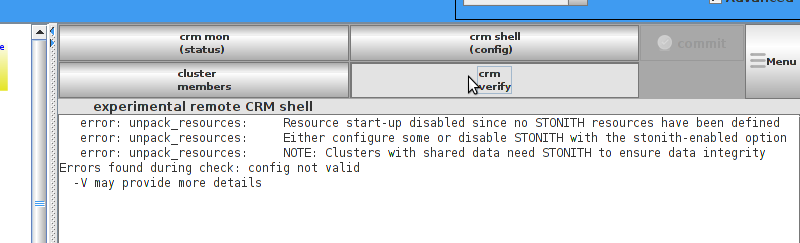
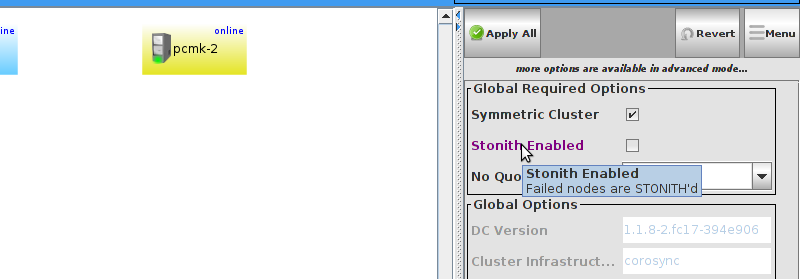
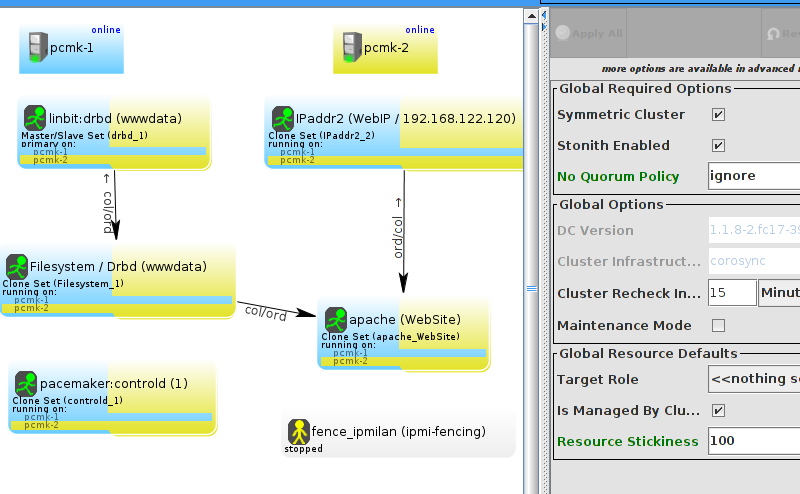
enabled. However it also knows when no STONITH configuration has been supplied and reports this as a problem (since the cluster would not be able to make progress if a situation requiring node fencing arose).
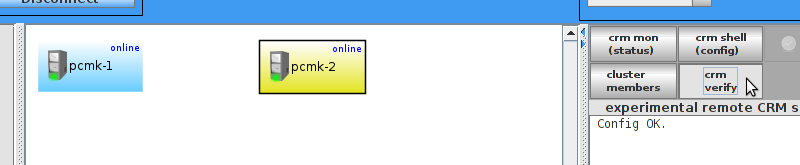
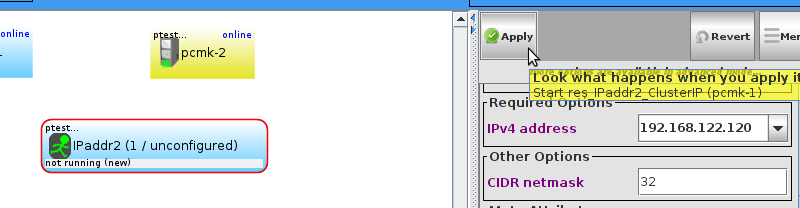
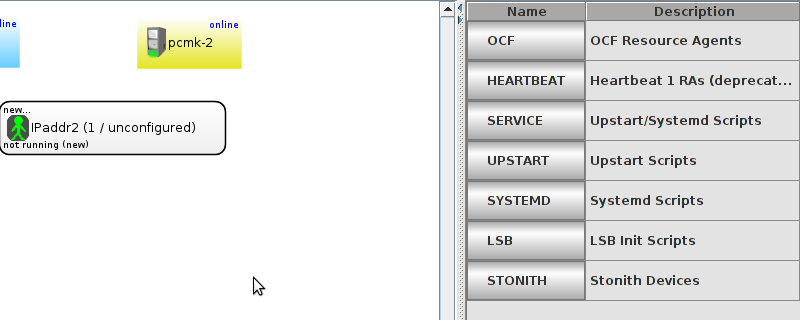
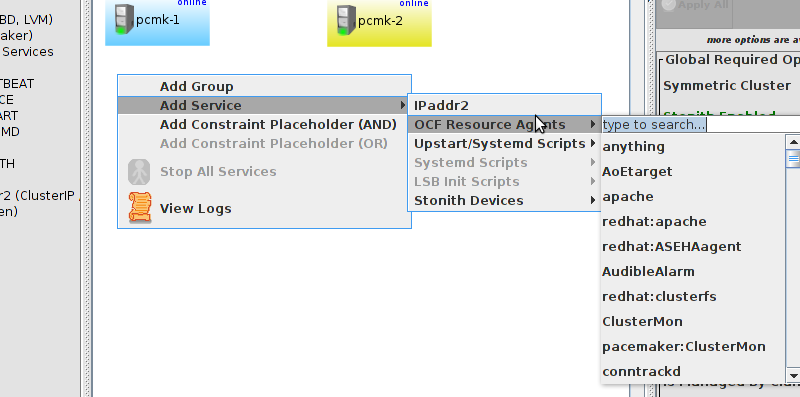
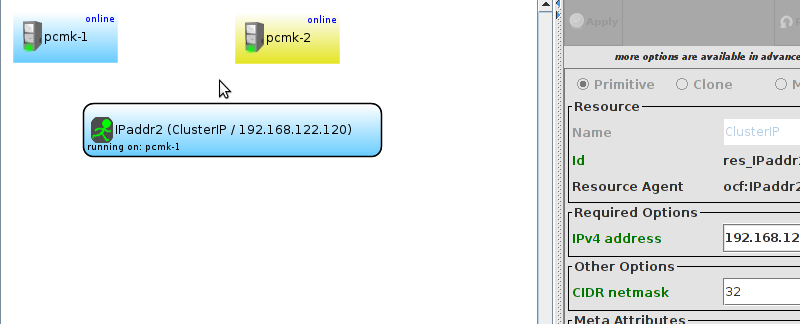
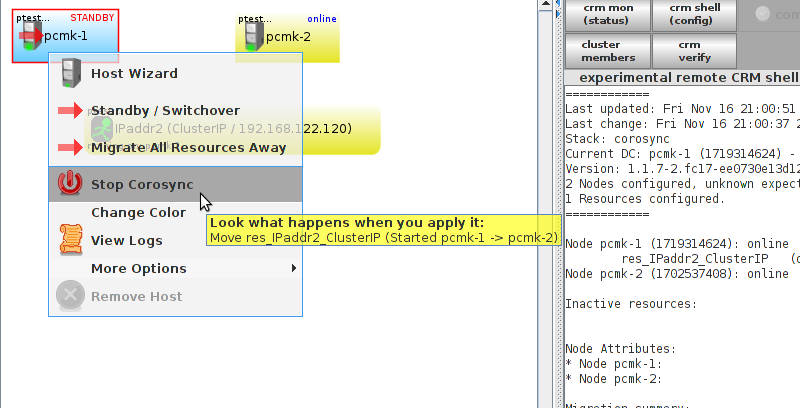
pcmk-1 is now offline. However we can also see that ClusterIP isn’t running anywhere!
total_nodes < 2 * active_nodes
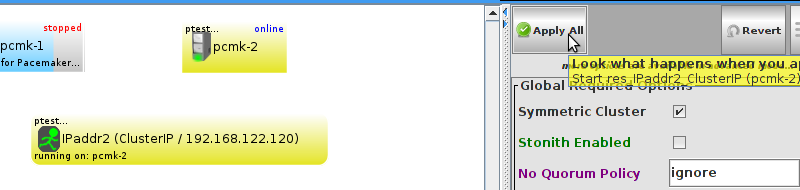

pcmk-1 and check the cluster’s status.
pcmk-1). Usually this is no longer the case.
Table of Contents
# cat <<-END >/var/www/html/index.html <html> <body>My Test Site - pcmk-1</body> </html> END
[root@pcmk-2 ~]# cat <<-END >/var/www/html/index.html <html> <body>My Test Site - pcmk-2</body> </html> END
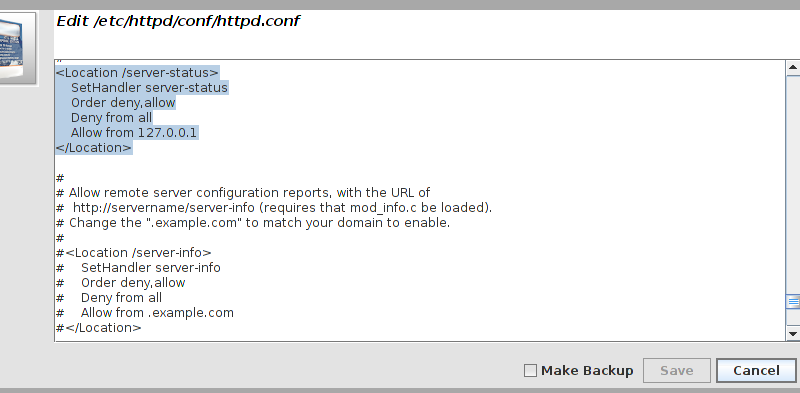
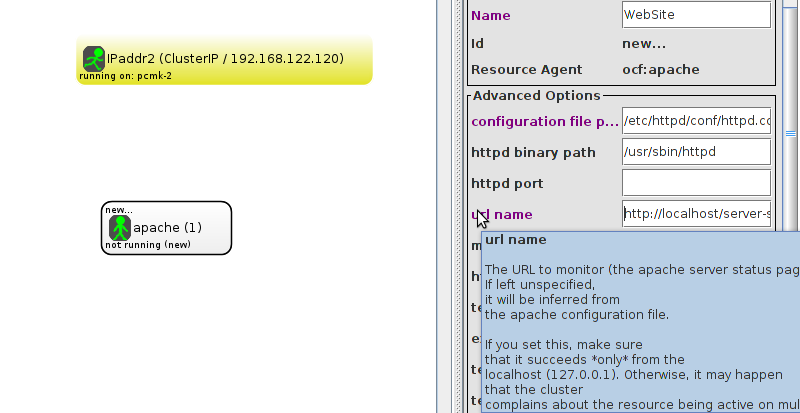

wget http://127.0.0.1/server-status
Connection refused in the output, then this is indeed the problem. Check to ensure that Allow from 127.0.0.1 is present for the <Location /server-status> block.
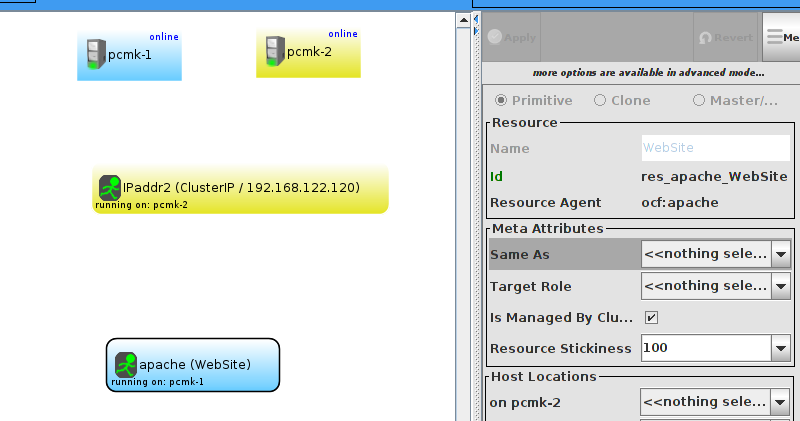
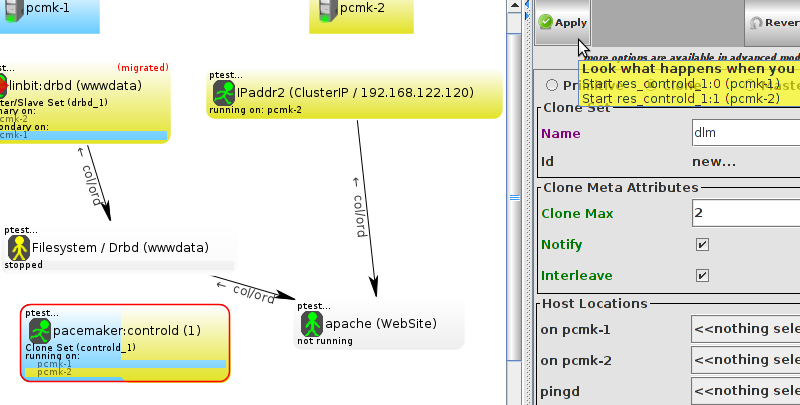
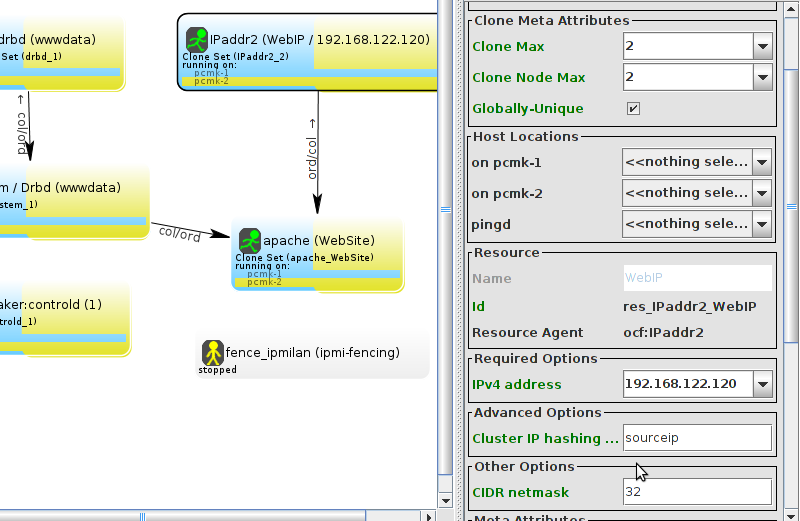
WebSite needs to be placed on the same machine as ClusterIP, this implies that we must know the location of ClusterIP before choosing a location for WebSite.
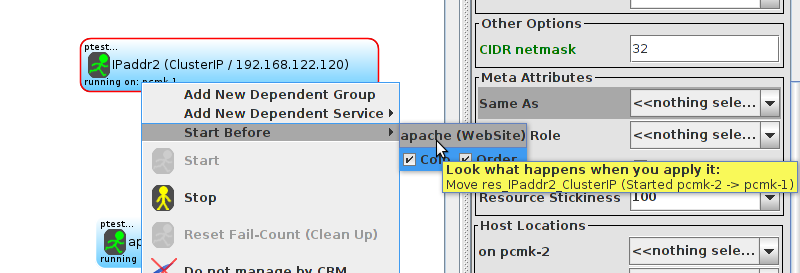
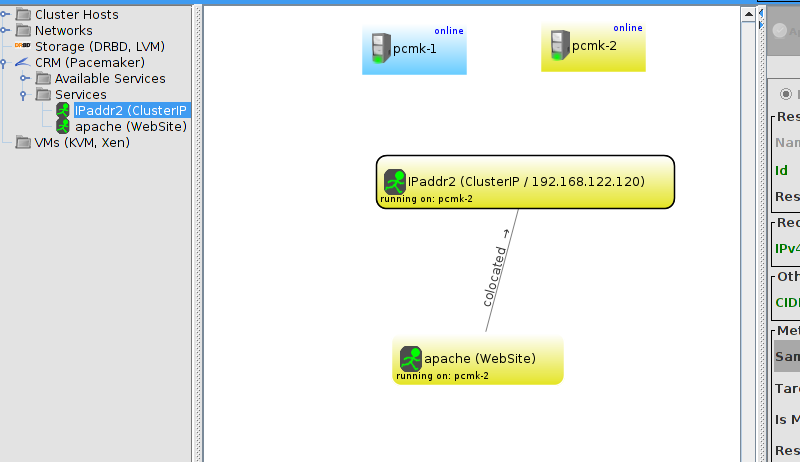
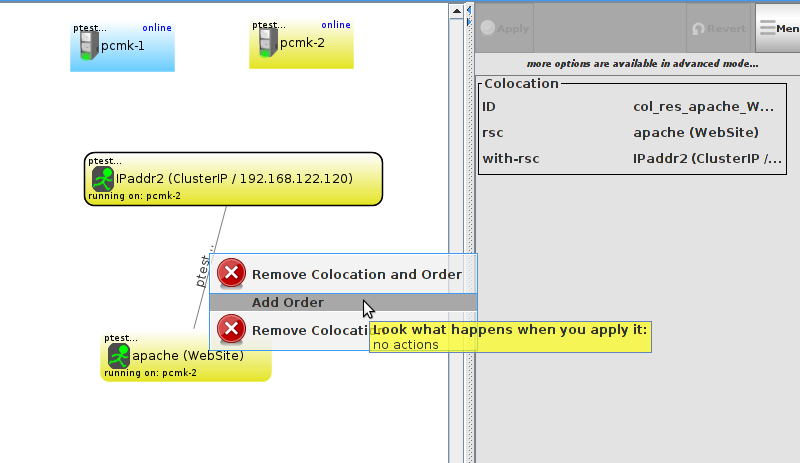
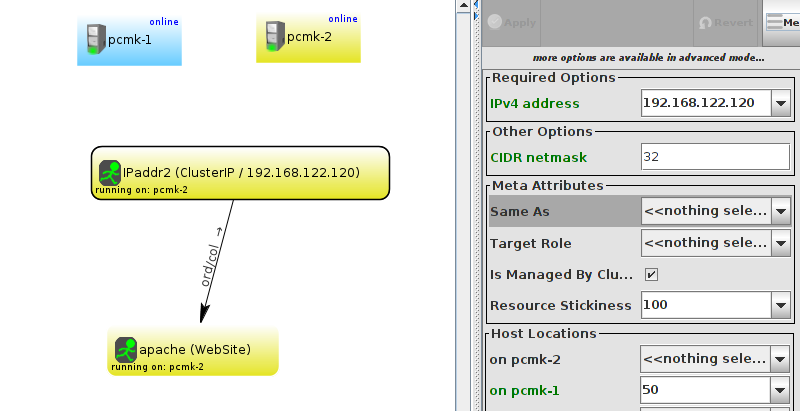
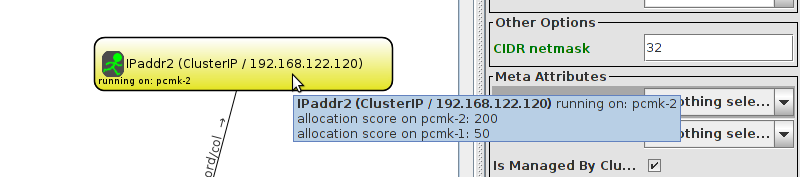
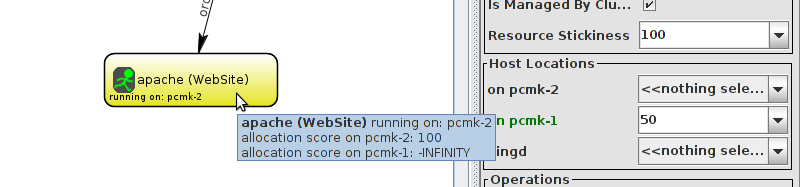
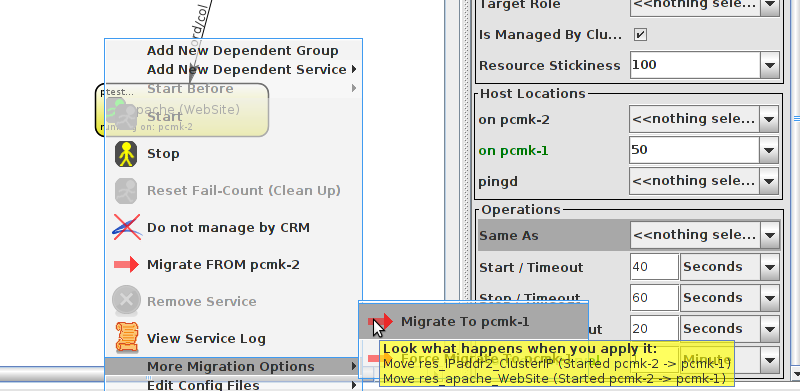
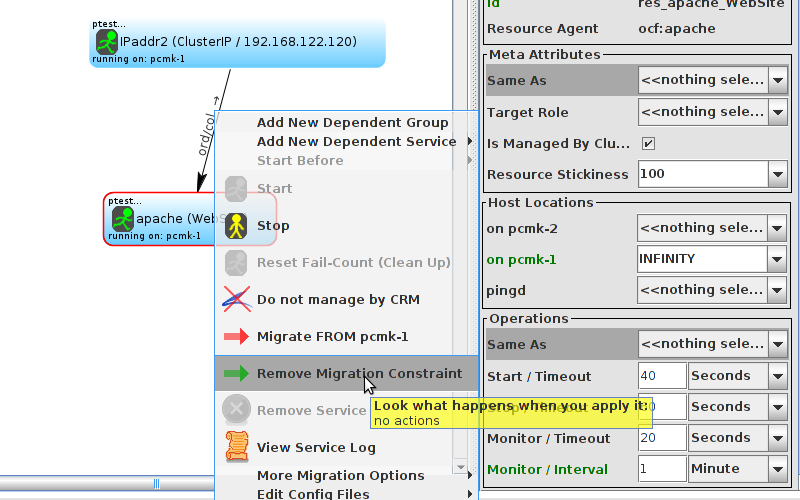
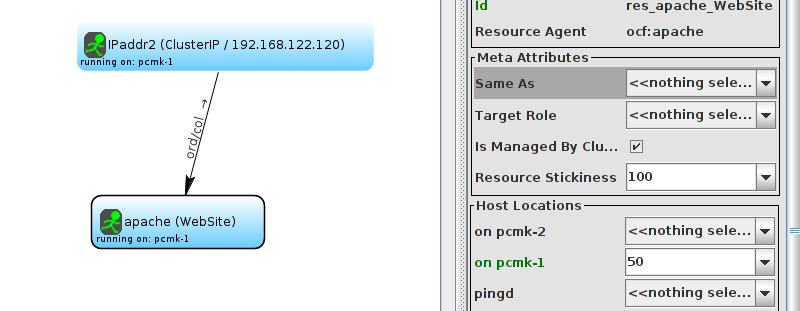
Table of Contents
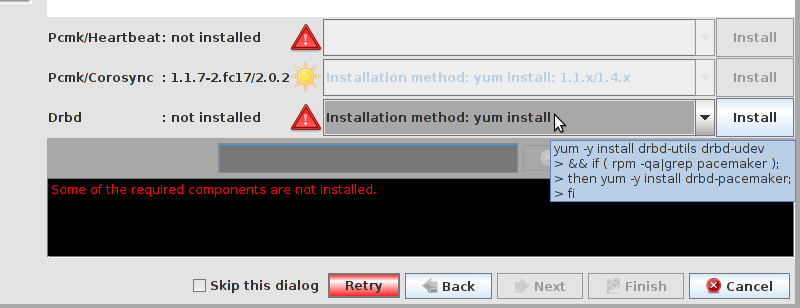
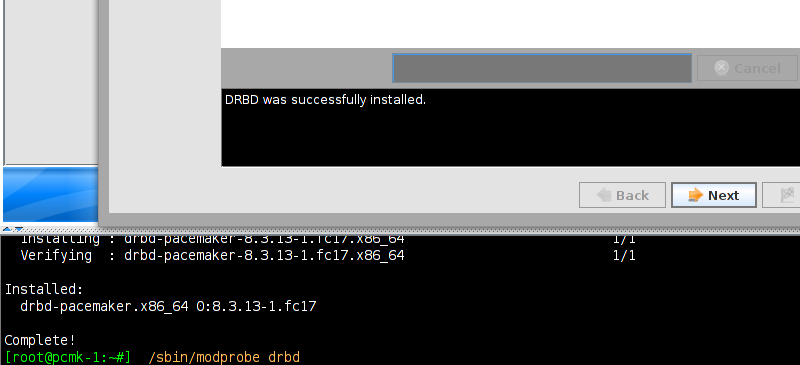

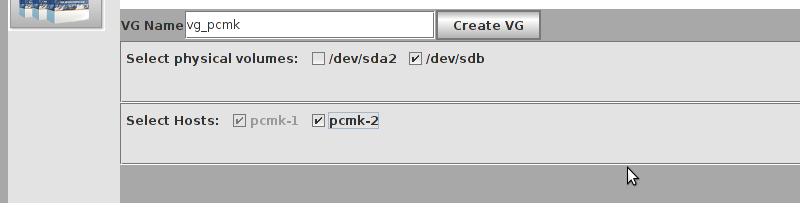
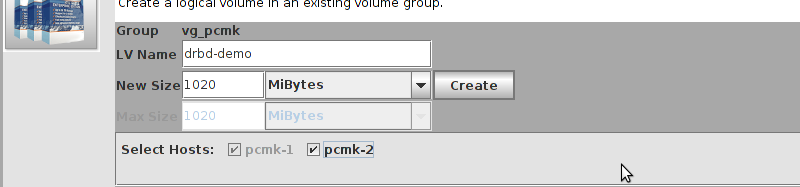
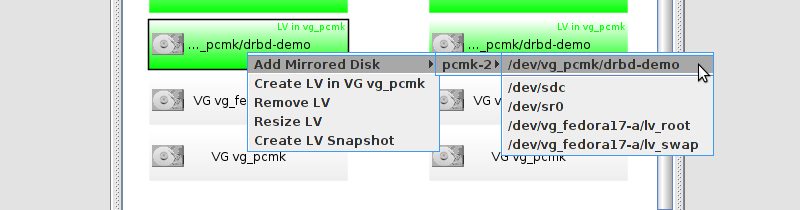
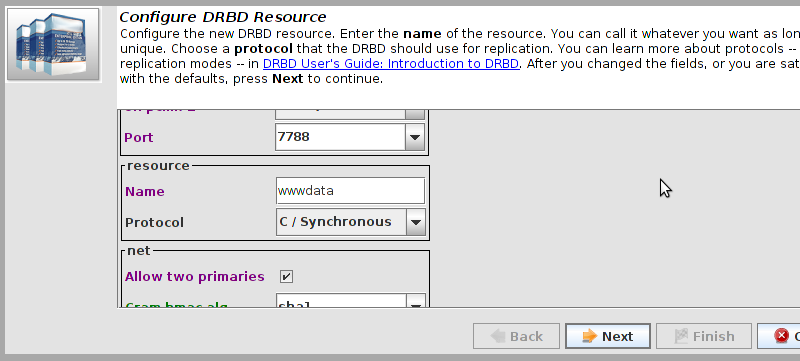
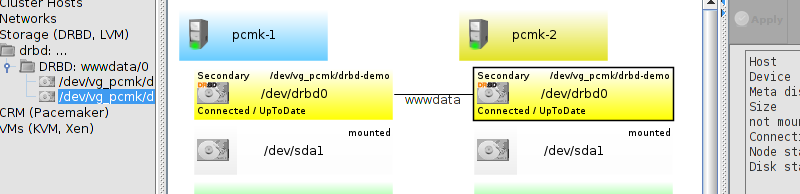
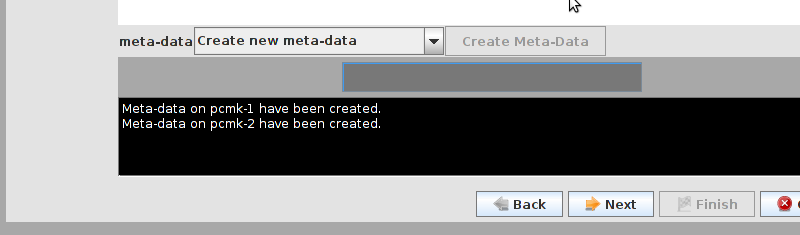
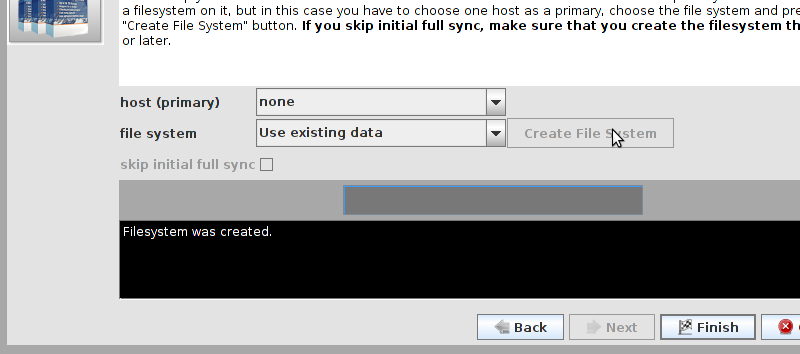
# mount /dev/drbd1 /mnt/ # cat <<-END >/mnt/index.html <html> <body>My Test Site - drbd</body> </html> END # umount /dev/drbd1
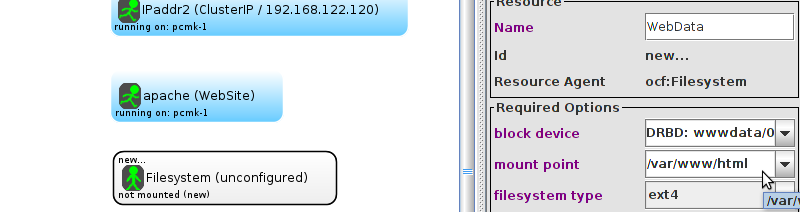
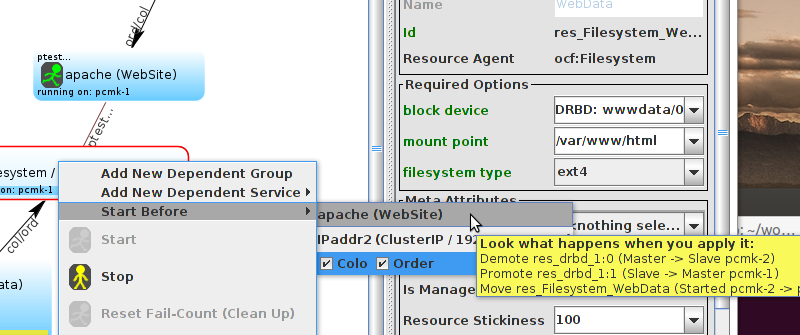
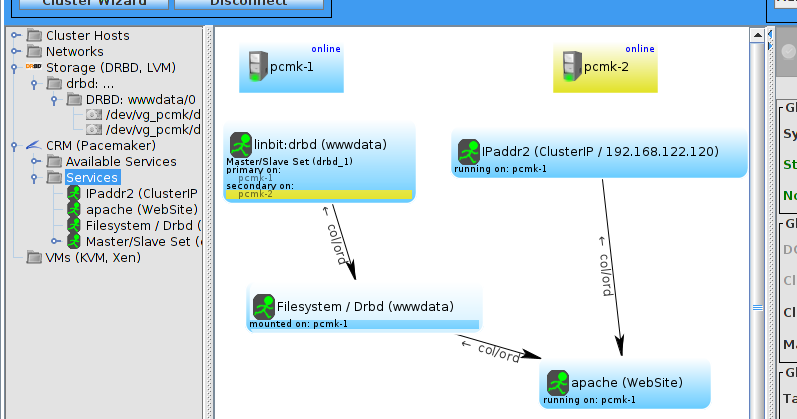
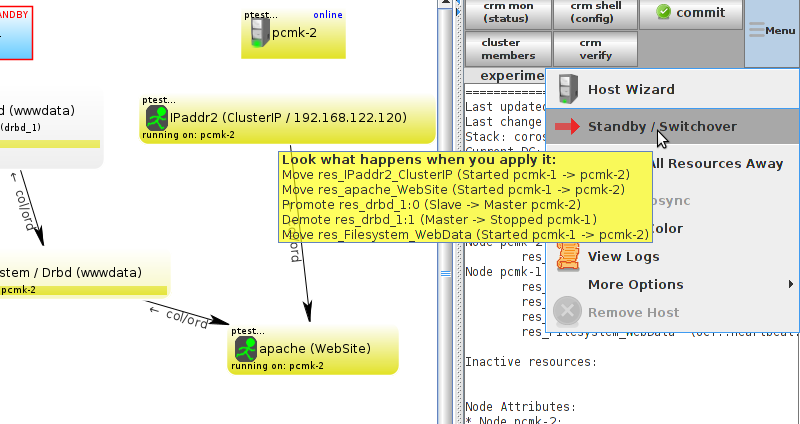
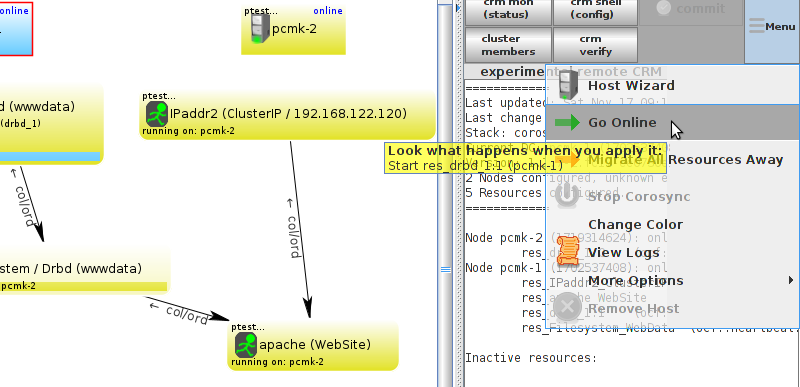
Table of Contents
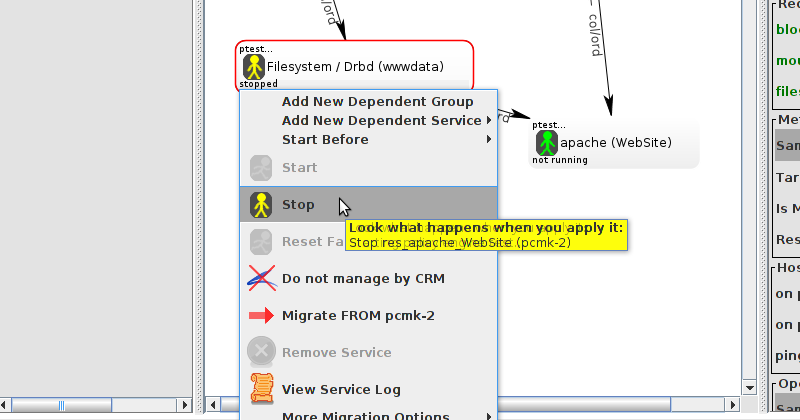
clustername:fsname. For the fsname, we need to use the same value as specified in corosync.conf for cluster_name. Just pick something unique and descriptive and add somewhere inside the totem block. For example:
totem {
version: 2
# cypto_cipher and crypto_hash: Used for mutual node authentication.
# If you choose to enable this, then do remember to create a shared
# secret with "corosync-keygen".
crypto_cipher: none
crypto_hash: none
cluster_name: mycluster
.../dev/drbd1: Read-only file system
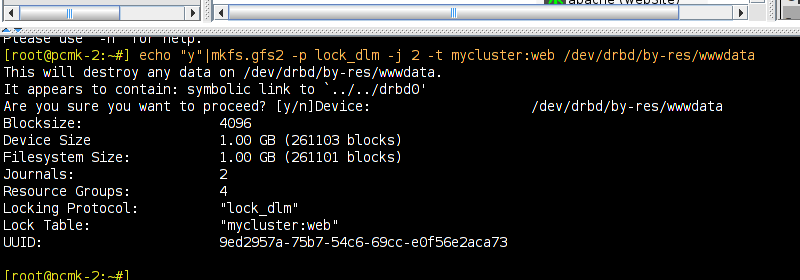
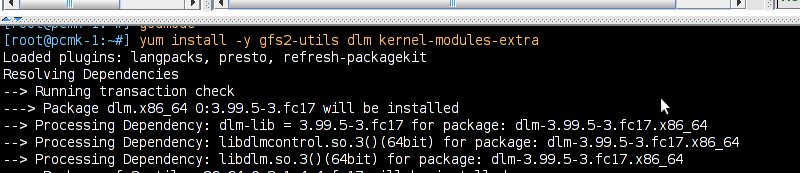
# mount /dev/drbd1 /mnt/ # cat <<-END >/mnt/index.html <html> <body>My Test Site - GFS2</body> </html> END # umount /dev/drbd1 # drbdadm verify wwwdata#

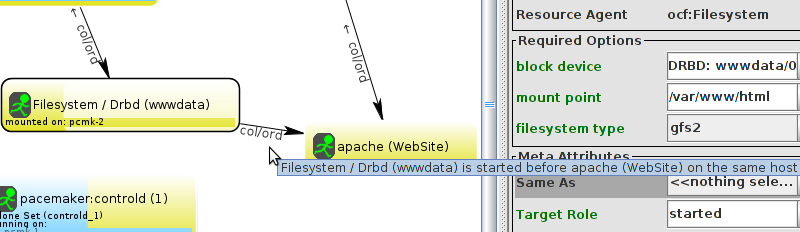
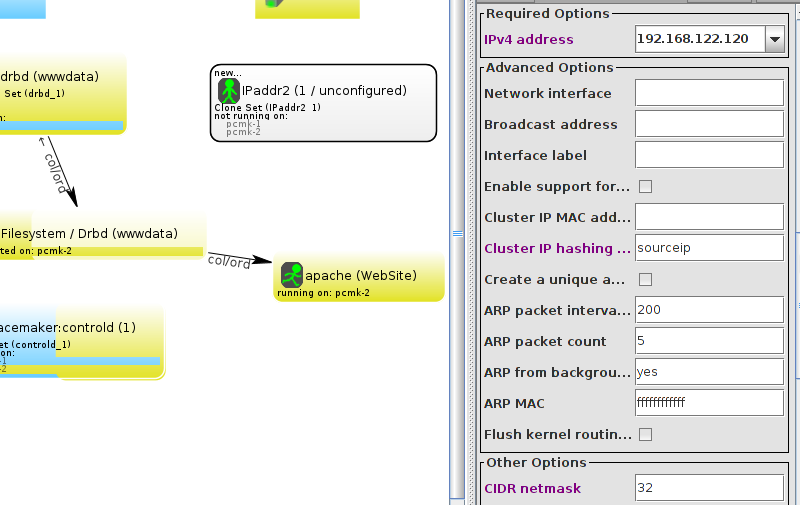
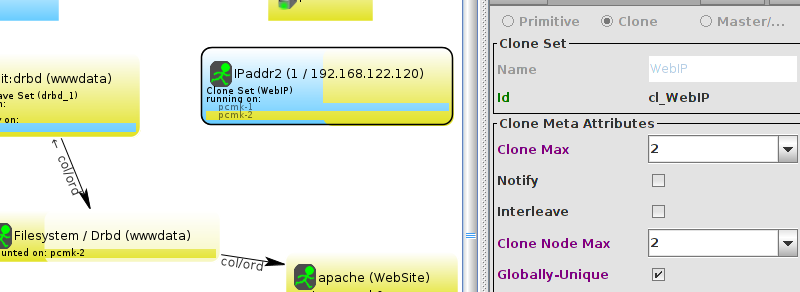
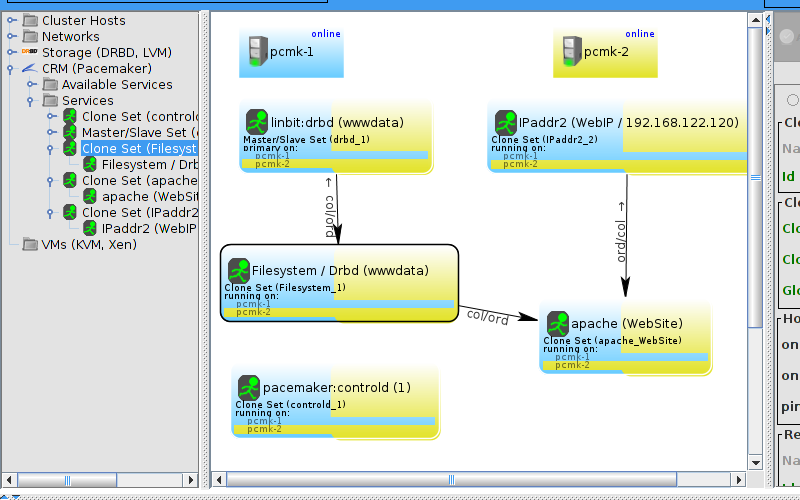
Table of Contents
pcmk_host_map parameter. See man stonithd for details.
pcmk_host_list and/or pcmk_host_check parameters. See man stonithd for details.
pcmk_host_argument parameter. See man stonithd for details.
stonith_admin --reboot nodename. Although you might want to stop the cluster on that machine first.
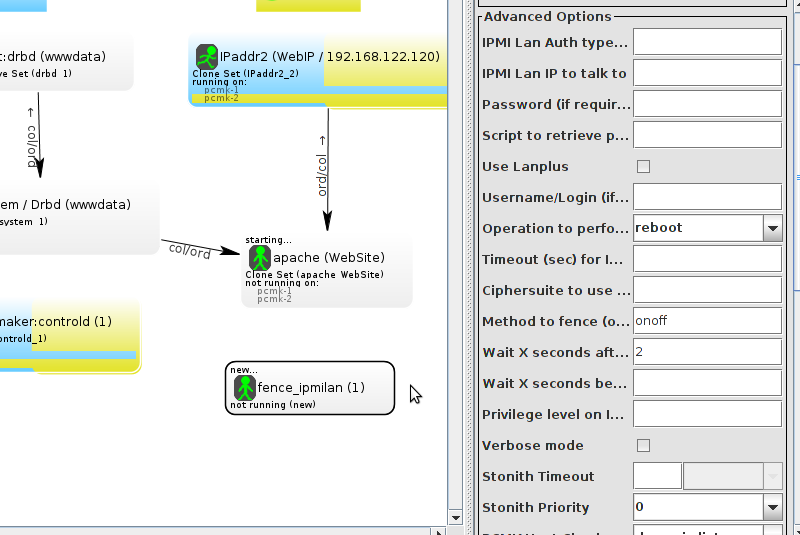
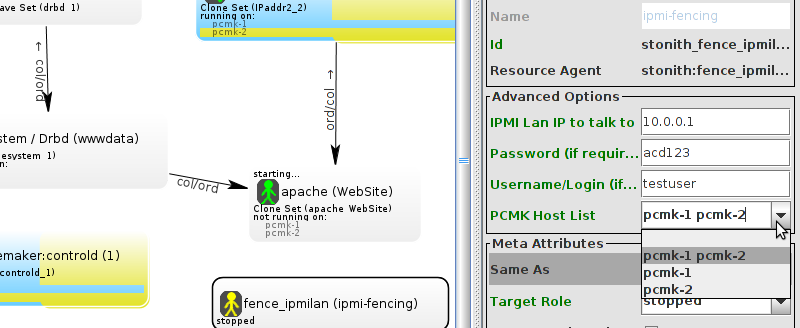

Table of Contents



# Please read the corosync.conf.5 manual page
totem {
version: 2
secauth: off
cluster_name: mycluster
transport: udpu
}
nodelist {
node {
ring0_addr: pcmk-1
nodeid: 1
}
node {
ring0_addr: pcmk-2
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_syslog: yes
}
| Revision History | |||
|---|---|---|---|
| Revision 1 | Mon May 17 2010 | ||
| |||
| Revision 2 | Wed Sep 22 2010 | ||
| |||
| Revision 3 | Wed Feb 9 2011 | ||
| |||
| Revision 4 | Wed Oct 5 2011 | ||
| |||
| Revision 5 | Fri Feb 10 2012 | ||
| |||
| Revision 6 | Tues July 3 2012 | ||
| |||
| Revision 7 | Fri Sept 14 2012 | ||
| |||